
There is a huge amount of excitement right now around large AI models. Every week new announcements appear about increasingly powerful systems that can write, analyse, code, summarise, and reason in ways that were difficult to imagine only a few years ago.
The message is often simple: the latest frontier models are the future, and organisations should integrate them as quickly as possible.
And while these models are incredibly capable, the reality — as with most technologies — is more nuanced.
AI models today broadly fall into two categories.
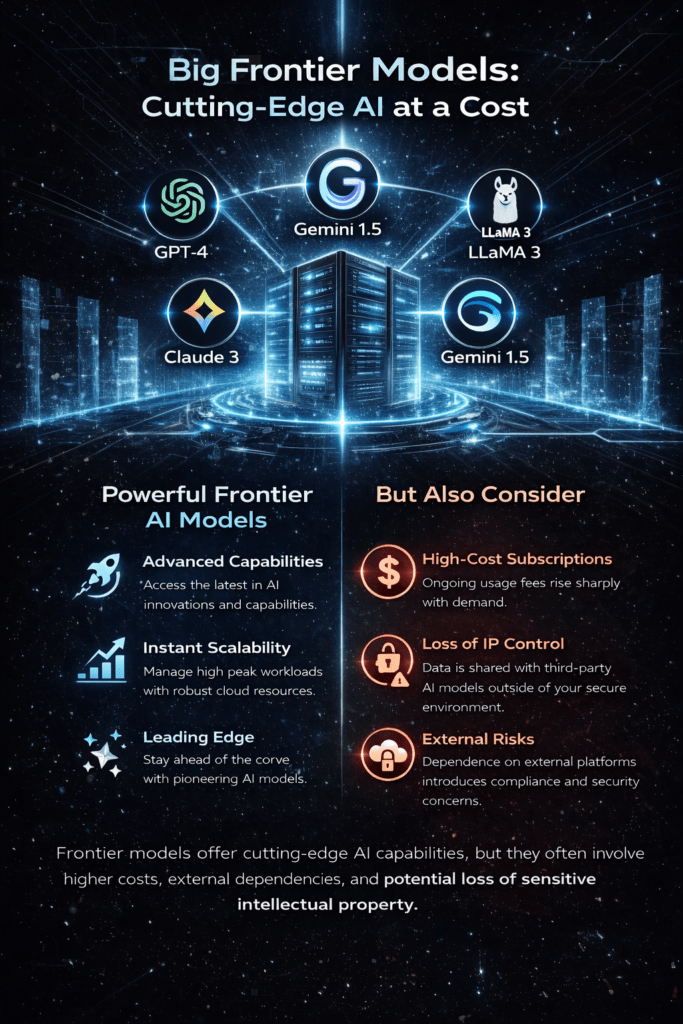
The first are frontier models. These are the large, highly advanced models built by major AI labs and accessed through cloud platforms. Systems such as GPT, Claude, Gemini, and similar models fall into this category. They are trained on enormous datasets using vast computing resources and often represent the cutting edge of what AI can currently do.
The second category is open-source models. These include models such as LLaMA, Mistral, Mixtral, Gemma, and Phi. While they may not always match the very latest frontier models in every benchmark, they have advanced rapidly and can now deliver extremely strong performance for many real-world applications.
More importantly, they offer something that cloud-based frontier models cannot always guarantee “Control”.
To understand why this matters, consider how most frontier models are used today.
When you send a prompt to a cloud-based AI system, your request — and often the information included in it — leaves your infrastructure and is processed by systems operated by another organisation. That may be perfectly acceptable for some tasks, but for others it raises important questions.
Where is the data stored?
Who has access to it?
How long is it retained?
Could it be used for training future models?
For organisations working with sensitive data, intellectual property, confidential documents, or regulated information, these questions are not theoretical. They are critical.
This is where open-source models offer a fundamentally different approach.
Instead of sending your data to the model, the model comes to your data.
Using tools such as Ollama and similar deployment frameworks, organisations can run large language models entirely within their own infrastructure. The models operate inside the same security boundaries as the rest of the organisation’s systems.
The data never leaves the environment.
For many businesses this changes the equation significantly.
Running models internally means data sovereignty remains intact. Sensitive information stays behind the firewall, governed by existing access controls, security policies, and compliance frameworks.
Intellectual property remains protected.
There are also practical considerations around cost.
Frontier models are typically accessed through usage-based APIs. As adoption grows, the cost can scale rapidly depending on the volume of requests, the size of the model being used, and the amount of data being processed.
For experimentation this may be perfectly manageable. But when AI becomes part of core business workflows, those costs can become substantial.
Open-source models offer a different economic model.
Once deployed within an organisation’s infrastructure, they can be used repeatedly without the same per-request cost structure. The organisation controls the hardware, the scale, and the workload.
This can make long-term AI adoption far more predictable.
None of this means that frontier models should not be used.
In many cases they are extremely valuable. They often represent the most advanced capabilities available at a given moment, particularly for complex reasoning, large context windows, and highly specialised tasks.
The real point is that no single model or approach is correct for every situation.
And this is where our philosophy comes in.
Rather than forcing organisations into a single ecosystem, we design systems that support choice.
Some organisations prioritise maximum security and full internal control. In those environments we deploy open-source models within secure infrastructure so that all data processing happens internally.
Other organisations may want to take advantage of frontier models for certain tasks where their capabilities provide clear advantages.
In many cases the most effective solution is a hybrid approach. Open-source models handle internal workflows and sensitive data processing, while frontier models are used selectively where their strengths provide additional value.
This flexibility ensures that organisations are not locked into one technology path.
They can adapt as models improve, as requirements change, and as the AI landscape continues to evolve.
AI is moving quickly, and the tools available today will continue to change over time.
What should not change is the ability for organisations to maintain control over their data, their systems, and their strategic decisions.
Our role is not to push a single technology.
Our role is to build intelligent systems that allow organisations to choose the right tools for the right problems, while ensuring security, ownership, and long-term sustainability remain at the centre of every solution.
Because in the end, the most powerful AI strategy is not just about the models themselves.
It is about having the freedom to choose how they are used.
Notifications
